記事
2023年7月18日
ChatGPTによる放射線診断クイズへの挑戦:GPT-4を用いた診断精度の検証
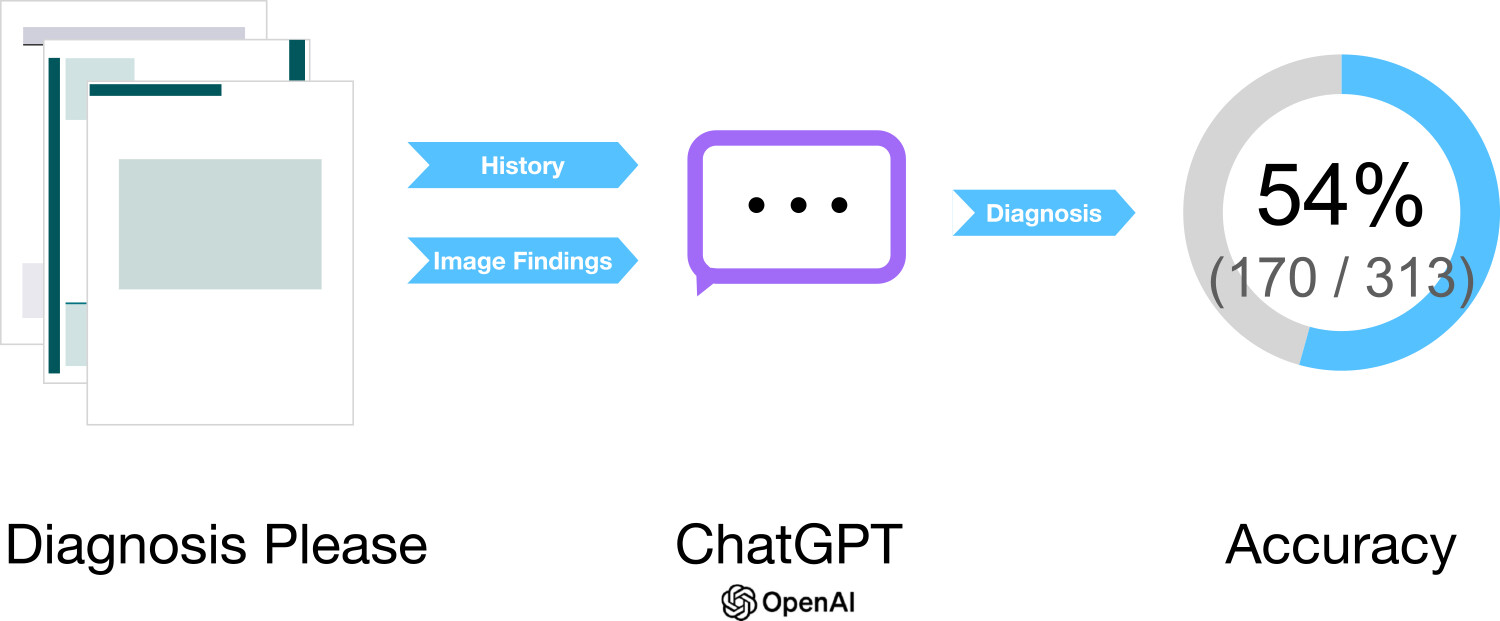
私たちは、大規模言語モデルであるGPT-4を搭載したChatGPTを用いて「Diagnosis Please」クイズに対する診断精度を検証し、最終的に約54%の正答率を示すことを明らかにしました。
論文
Diagnostic Performance of ChatGPT from Patient History and Imaging Findings on the Diagnosis Please Quizzes
Radiology
https://doi.org/10.1148/radiol.231040
著者談
ChatGPTにGPT-4が登場したばかりのころ、私たちは技術に感動し、この研究を一気に仕上げることを決めました。近年、医療分野でも大規模言語モデルを活用した検証が増えていますが、そのはしりともいえる時期に論文をまとめられたのは、刺激的な経験でした。さらに、Radiologyの編集委員会とは何度もやりとりを重ねました。最初はオリジナル論文として投稿していたものを、最終的にshort articleに転換する条件で合意できたのも、彼らがやり取りの中で「あなたの情熱を感じた」と好意的に受けとめてくれたからだと考えています。特に投稿過程での粘り強い編集委員会との議論は、私たちの研究に対する思い入れを強くしてくれました。
論文概要
本論文は、Radiologyが定期的に掲載している「Diagnosis Please」クイズを対象として、GPT-4ベースのChatGPTがどこまで的確に最終診断を導けるかを調べた研究です。診断には患者の病歴と医用画像所見という、実臨床でも重要な情報源を段階的に与えました。ただし、ChatGPT自体は画像を直接読み取れないため、私たちが論文から抽出した所見をテキストとして提示し、その結果を二人の放射線科医が評価しました。合計313症例を使ったところ、患者の病歴だけで診断を行った場合の正答率は22%でしたが、画像所見を加えると57%に向上し、両方を合わせると61%という精度になりました。そして、最終的に1つの確定診断を出すという問いに対しては、全体として54%の正答率を示しました。
論文詳細
本研究は1998年から2023年までに掲載された313症例を対象とし、それぞれのクイズにおける「患者の病歴」「提示された画像所見」「両方を併せた情報」の三段階でChatGPTに鑑別診断を挙げさせました。その後、最終診断を一つ選択させ、Radiologyに掲載の正解と一致するかを評価しています。解析の結果、両時点で統計的に有意差は認められなかったものの、September 2021以前の症例も含めて学習されている可能性を踏まえると、想定よりも堅実なパフォーマンスといえます。特に心血管系の症例では79%の高い正答率を示したのに対して、筋骨格系では42%にとどまるなど、診療領域による差もはっきり現れました。ChatGPTが挙げた鑑別診断の妥当性を専門医が5段階で評価したところ、中央値は5.0に達し、総じて十分に納得感があることがわかりました。ただし、今回のクイズ形式は実臨床環境に比べて制約が多く、またChatGPTは画像を直接参照できないという弱点もあります。それでも、放射線科医不足が指摘される中で、こうしたAIによる即時的な意思決定支援の可能性を示せた点は有意義だと考えています。結果的に、私たちはChatGPTの適度な信頼性を確認できましたが、全診療領域で一様に有効とはいえず、今後はさらなる検証が必要だと認識しています。